
utworzone przez Marcin Żmigrodzki
 Jako Partner wydarzenia zapraszamy Was na drugą edycję konferencji organizowanej przez Women in Project Management PMI PC, „Kobieca moc w projektach” – 17 maja w Poznaniu.
Jako Partner wydarzenia zapraszamy Was na drugą edycję konferencji organizowanej przez Women in Project Management PMI PC, „Kobieca moc w projektach” – 17 maja w Poznaniu.
Wydarzenie: Konferencja Women in Project Management 2024, Kobieca moc w projektach
Kiedy:17.05.2024,
Miejsce: Poznań, Hotel HP Park
Organizatorzy zapewniają porcję wiedzy, inspiracji, nowych trendów i doświadczenia. A to wszystko okraszone networkingiem!
Sprzedaż biletów już ruszyła, zadbaj o wejściówkę dla siebie!
Interesują Cię bilety grupowe? Masz inne pytania? Pisz na adres wipm@pmi.org.pl
Informacje i bilety: https://wipm.pmi.org.pl

utworzone przez Marcin Żmigrodzki

Grupa Speakleash udostępniła właśnie wytrenowany na polskich tekstach model językowy Bielik. Piszę o tym z dumą, bo od początku kibicuję Spichlerzowi i trzymam kciuki, aby udało im się stworzyć technologię na światowym poziomie.
Speakleash (Spichlerz) ruszył dwa lata temu z zadaniem zebrania największego w historii zbioru tekstów po polsku. Wolontariusze celowali w 1TB danych. Tak gigantyczny zbiór miał być podstawą do tworzenia nowych algorytmów i usług w specyfice języka polskiego. Jak wiadomo GPT, Claude, Gemini, Mixtral nie są trenowane dla naszego języka.
Po dwóch latach udało się i ekipa przystąpiła do drugiego kroku, wytrenowania pierwszego wielkiego modelu językowego, który stałby się konkurencją dla światowych gigantów. I znowu się udało. Właśnie został zaprezentowany Bielik. Pierwszy czysto polski olbrzymi model językowy.
Dzisiaj każdy może sam sprawdzić, jak Bielik działa. A działa całkiem nieźle, choć potrzebuje jeszcze dotrenowania, bo jest wciąż pisklakiem, który wczoraj wyleciał z gniazda. Świetnie analizuje gramatykę, streszcza po polsku i odpowiada na ogólne pytania. Prawdopodobnie dobrze sprawdzi się w architekturze RAG dla polskich baz wiedzy. Jeszcze trochę halucynuje, ale cały czas karmiony jest przez troskliwe stado informatyków.
Link do wypróbowania Bielika można znaleźć tutaj: https://huggingface.co/spaces/speakleash/Bielik-7B-Instruct-v0.1
Link do projektu Spichlerz: https://speakleash.org/
utworzone przez Marcin Żmigrodzki
Historia tego, jak powstała baza wiedzy w systemie Wroolo i jak ją wykorzystuję na codzień.
Pisząc książkę o zwinnych projektach, zacząłem gromadzić sporo treści. Jedne od razu cytowałem w rozdziałach, a inne wydawały się inspirujące, ale nie do wykorzystania od razu. Z czasem nazbierało się dziesiątki cytatów i PDFów. Niesamowitym źródłem dla mnie był na przykład ResearchGate. To serwis z publikacjami naukowymi. Zdarzało mi się, że nawet jeżeli artykuł nie był dostępny w pełnej treści, wiadomość do autora wystarczała, aby go dostać.
Wiedzy przybywało, projekt książka rozkręcał się i coraz trudniej było mi znaleźć potrzebne fragmenty. W pewnym momencie przekroczył poziom 200 porcji wiedzy. Część z nich zapisywałem w postaci dokumentów na Google Drive, ale wyszukiwanie w tym jest trudne, szczególnie, gdy szukasz czegoś, co składa się z jednego zdania.
Postanowiłem ułatwić sobie życie, ale najpierw je utrudniłem. Bowiem zaprojektowałem bazę wiedzy dostępną przez WWW. Pierwotnie przypominała feed z instagrama, i to działało mi całkiem nieźle dopóki liczba postów nie przekroczyła 50. Poniżej przedstawiam próbkę takiego feeda.

Ale wiedzy przybywało. Zacząłem kopiować fragmenty stron WWW, skany stron z książek i linki. Okazało się, że dodawanie nowej wiedzy musi być maksymalnie proste. Po prostu kopiuj – wklej i system musi zrobić resztę. Tak narodził się inspirowany Notion, Nuclino i notatnikami laboratoryjnymi edytor składający się z wielu pól o różnych typach. Poniżej załączam przykład losowej strony wklejonej do tego edytora.
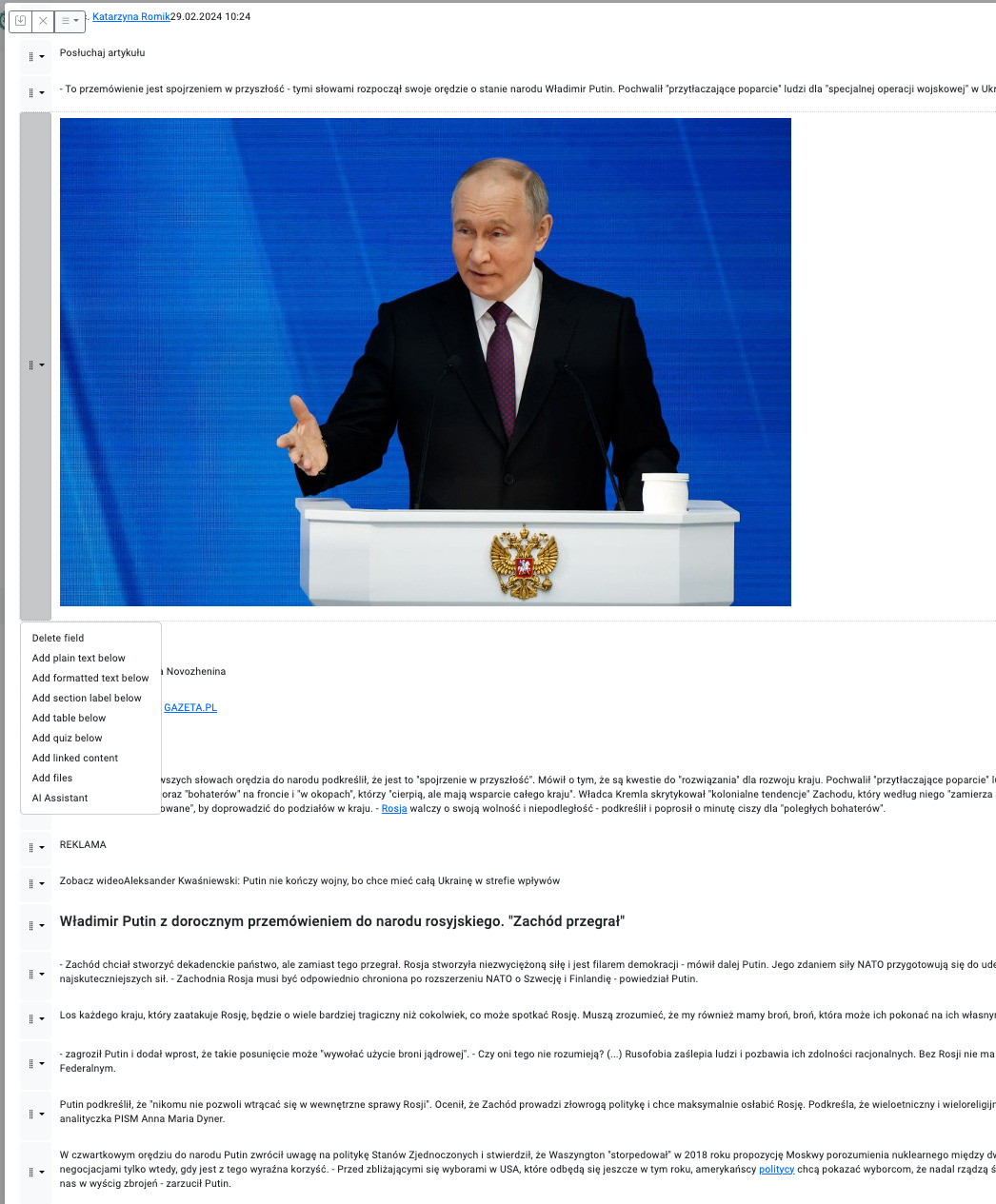
Poszczególne sekcje można przesuwać, usuwać, dodawać nowe.
I mniej więcej wtedy pojawił się GPT, a chwilę później Sebastian Kondracki opowiedział mi o modelu RAG. I bam, miesiąc później miałem wyszukiwarkę semantyczną niezależną od języka. Mogłem po polsku wyszukać angielskie treści i na odwrót. To był przełom. Ponieważ dotarcie do dowolnej wiedzy zabierało mi raptem kilka sekund, to zacząłem wrzucać wszystko, co wydało się interesujące, jak leci. Algorytm i tak to odnajdzie, gdy będę potrzebował.
Na poniższym przykładzie widać, jak na hasło w języku polskim system wynalazł artykuły w PDF po angielsku.

Ale RAG to nie tylko wyszukiwanie, ale również dyskusja z własnymi dokumentami. Znalezione treści są wysyłane w postaci prompta to GPT, a ten w odpowiedzi generuje wiedzę. Teraz, gdy potrzebuję szybko znaleźć jakiś drobny fakt, to po prostu rozmawiam z moim prywatnym mentorem. Jeżeli dana wiedza znajduje się w znalezionych dokumentach i pytanie jest dość precyzyjne, to naprawdę działa rewelacyjnie. W przypadku chatu zauważyłem, że lepiej działa jednak po angielsku.
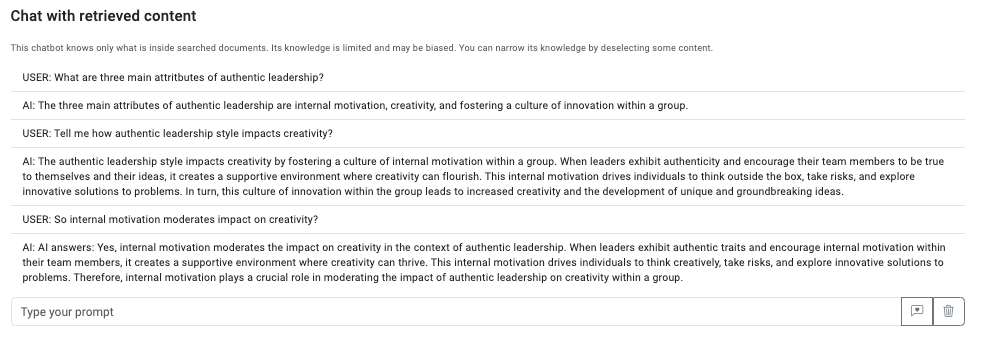
Oczywiście, jak to LLM, czasem halucynuje, więc przed zastosowaniem wiedzy warto sprawdzić źródła, ale mam je poniżej, wiec to jest dość szybkie.
W ten sposób rozwinąłem bazę wiedzy o pojemności 200 wpisów, która stała się dla mnie codziennym towarzyszem w pisaniu książki Bardziej niż Agile. Gdy zorientowałem się, że moduł wiedzy w systemie Wroolo wpisuje się w obszar nazwany PKMS (Personal Knowledge Management System), doszedłem do wniosku, że wpisuje się również w grupowe zarządzanie wiedzą.
Natychmiastowym eksperymentem było stworzenie bazy wiedzy na temat zarządzania projektami, którą utworzyłem z wpisów z bloga, książek i portalu wiedzy Octigo. Łącznie uzbierałem 600 porcji wiedzy i udostępniłem go moim studentom i absolwentom. Dzisiaj korzysta z niej kilkuset użytkowników. Większość pewnie w celu przygotowania się do egzaminu na studiach 🙂
Sądzę, że upowszechnienie architektury RAG i jednocześnie wprowadzenie ułatwień wprowadzania wiedzy i jej opisywania, mogą zlikwidować główną barierę zarządzania wiedzą, jaka doprowadziła do zarzucenia tej koncepcji 20 lat temu. Wiem, co mówię, bo niegdyś zrobiłem z tego doktorat i zmieniłem branżę 🙂
Sytuacja, gdy wystarczy zrobić kopiuj / wklej dowolnej treści, bez konieczności tagowania, opisywania, kategoryzowania, bardzo ułatwia budowanie bazy wiedzy. A sytuacja. gdy mogę wpisać dowolne zapytanie i uzyskać nie tylko pasujący artykuł, ale i bezpośrednią odpowiedź zdecydowanie zachęca do korzystania z takiej bazy wiedzy.
Gdyby zainteresował Was system Wroolo, to serdecznie zapraszam do przetestowania go na wroolo.com.
Baza wiedzy to połowa systemu Wroolo, jednak o drugiej połowie jeszcze nie piszę, bo ciągle ją dopieszczam. Będzie koncentrowała się na zarządzaniu zadaniami, ale w specyficzny sposób. Pozwalający na połączenie świata zwinnego z kaskadowym.
Zakładam, że do osobistego użytku Wroolo będzie darmowy. Ewentualny model biznesowy chcę oprzeć na zespołach projektowych.

utworzone przez Marcin Żmigrodzki
 Gotowa jest nasza nowa symulacja szkoleniowo – integracyjna Scrum City. Symulacja jest krótka i intensywna. Trwa od 2 do 4 godzin i demonstruje w praktyczny sposób, jak zespół może wspólnie budować innowacyjne rozwiązanie, stosując Scrum.
Gotowa jest nasza nowa symulacja szkoleniowo – integracyjna Scrum City. Symulacja jest krótka i intensywna. Trwa od 2 do 4 godzin i demonstruje w praktyczny sposób, jak zespół może wspólnie budować innowacyjne rozwiązanie, stosując Scrum.
Więcej o Scrum City znajdziesz tutaj.
Scrum City zaplanowane jest na 2-3 godziny, więc może być rozgrywane w ramach większego szkolenia o zwinnym zarządzaniu projektami, jak i jako niezależny blok w ramach działań integracyjnych lub konferencji.
Do rozgrywki potrzeba pudełka z klockami, kilku podkładek, na których się buduje, plastikowych kart backlogu i timerów do mierzenia czasów sprintów. Niczego się nie drukuje, nic się nie zużywa.
Symulacja była rozwijana przez nas długo, bo przyświecało nam założenie, że musi być prosta do poprowadzenia przez niezależnego trenera i trwała. Naszą dodatkową, a właściwie pierwszą intencją było wsparcie nauczycieli w edukacji młodzieży na temat zasad współpracy. Teraz zamierzamy rozpocząć prace z zaprzyjaźnionymi szkołami. Mamy nadzieję ustalić możliwy zakres jej wykorzystania, bo świetnie się wpisuje w przedmiot Biznes i Zarządzanie na poziomie szkół średnich.
Symulacja jest także dostępna komercyjnie. Wprowadzenie trenera zajmuje około godziny.
Jeżeli jesteś zainteresowany samodzielny jej poprowadzeniem, to zapraszamy do kontaktu: szkolenia@octigo.pl.

utworzone przez Marcin Żmigrodzki
 Zabawa wyobraźnią
Zabawa wyobraźnią
Gdybyśmy przewinęli czas pięć lat naprzód, zobaczylibyśmy nieskończoną liczbę możliwych scenariuszy. Jedne bardziej prawdopodobne, inne mniej. Zaryzykowałem i stosując posiadaną wiedzę spróbowałem opisać moim zdaniem dość prawdopodobny scenariusz w aspekcie zarządzania projektami IT. Ale wróćmy do marca 2024 roku.
Dysponujemy czterema podejściami do zarządzania projektami: kaskadowym (20 tysięcy lat), zwinnym (30-20 lat), optymalizacyjnym (około 60-40 lat), eksploracyjnym (?). Jednak rewolucja AI właśnie się zaczęła. Pierwsze algorytmy rozwiązujące uniwersalne problemy, w przeciwieństwie do poprzedniej klasy AI, która była dedykowana tylko do jednego typu zadania, właśnie dowiodły swojej wartości w obszarze generowania tekstów, obrazów, dźwięków, muzyki i nawet wideo.
Wędrujemy do przodu na osi czasu. Po roku już mało kto kwestionuje użyteczności modeli LLM i innych, tak jak mało kto kwestionuje użyteczność wyszukiwarki internetowej. Rozwiązania się mnożą. Następuje zachłyśnięcie optymalizacją kosztową, jaką niesie nowa technologia. Wszędzie tam, gdzie pracownicy w sposób powtarzalny przetwarzają informacje tekstowe, obrazowe, dźwiękowe, filmowe, następują stopniowe transformacje AI. Ludzie zmieniają zawody i przenoszą się do dziedzin, które oferują trochę trwalszą przewagę nad algorytmami sztucznej inteligencji: posady kreatywne, związane z relacjami z ludźmi, wymagające brania odpowiedzialności za decyzje lub wymagające chwytnych dłoni i przeciwstawnych kciuków. Właściwie nie ma pracownika firmy, który przynajmniej kilka razy dziennie nie wspierałby się rozwiązaniami klasy AI, do streszczania za długich tekstów (nigdy więcej Too Long Didn’t Read), do tłumaczenia, do przypominania spotkań i zadań, do wyszukiwania, ostrzegania o szczególnych sytuacjach. Ale to dopiero początek.
W pewnym momencie zaufanie do systemów AI wzrośnie na tyle, że pozwoli im się podejmować decyzje w biznesie. Skupmy się na świecie projektów. Głównym kryterium optymalizacji jest przez ostatnie lata jest moim zdaniem wskaźnik Time To Market. Aby go skracać, narodził się agile, product discovery i kilka innych koncepcji. Presja na coraz krótszy Time To Market (TTM) wzmoże się jeszcze bardziej, a wyścig między firmami przybierze na sile. Przełomowe innowacje zejdą z poziomu strategicznego (lat) na poziom taktyczny (miesięcy). A optymalizacje produktów zejdą z poziomu taktycznego (miesiące) na operacyjny (dni). To będzie mogło być możliwe dzięki dwóm czynnikom: spadającemu kosztowi nanoszenia zmian i spadającemu progowi kompetencyjnemu.
Dobrym przykładem z dzisiaj są technologie Low code/No code pozwalające szybko tworzyć standardowe systemy, które w wielu miejscach zastępują z powodzeniem dorosłe rozwiązania. Innym przykładem jest tworzenie zapytań do baz danych i hurtowni, niegdyś wymagały znajomości składni SQL, dzisiaj można pytać językiem naturalnym. Na etapie prototypu jest szereg rozwiązań pozwalających tworzyć strony internetowe na podstawie prompta (ciekawa lista takich narzędzi). Jak wieszczy prezes Nvidia, w krótkim czasie przestaniemy potrzebować programistów, bo kod będzie pisany językiem naturalnym.
Zatem, jak może za kilka lat wyglądać zespół projektowy w obszarze IT?
Wyobrażam sobie, że nadal potrzeba osób, które będą miały pomysł. Zrozumieją problem biznesowy i postawią właściwe pytania. Tyle, że postawią je nie sobie a algorytmom AI. Rozwiązanie techniczne będzie powstawać przez zadawanie dziesiątek pytań i generowanie kolejnych wersji oprogramowania. To przypomina sylwetkę analityka biznesowo/systemowego. Dzisiaj takie systemy, jak choćby mój GoodBA, czy Dot Chart, działają na dość prostym poziomie. Brak im głębi, ale patrząc na dynamikę rozwoju, coś co nie istniało rok temu, za rok może mieć potworne możliwości.
Zatem mamy niewielką grupę analityków, którzy zlecają zadania algorytmom. W efekcie w jedną godzinę może powstać 10, 20, 50 wersji systemów, które następnie są weryfikowane przez inne algorytmy. Przecież istnieją już dzisiaj automatyczne testy, a za chwilę mogą pojawić się automatyczne testy użytkownika. Wystarczy, że jeszcze jednemu algorytmowi analityk powie, żeby wszedł w rolę użytkownika o danym profilu o ocenił sposób korzystania z proponowanych 50 wersji systemu, a na koniec wybrał najfajniejszy z nich.
Tak, jak dzisiaj w trakcie odkrywania potrzeb użytkownika zespół tworzy jeden, dwa lub nawet trzy warianty funkcji (przykładowe testy A/B wymagają dwóch wariantów), tak za kilka lat normą może być tworzenie średnio 86 wariantów dla każdej z 50 funkcji. Co z tego, że to daje 86 do potęgi 50. Automatyczne heurystyki pozwolą wyeliminować najmniej obiecujące kombinacje i zacząć od tych potencjalnie dobrych. W ten sposób zespół otrzyma las wariantów tworzonego rozwiązania i jego zadaniem będzie znaleźć najoptymalniejszą ścieżkę pokonania go.
Aby skutecznie maszerować przez las wariantów rozwiązania, zespół musi szybko eliminować ślepe ścieżki. Zatem nadal będzie spotykał się i rozmawiał o kierunkach prac, a potem każdy członek zespołu wróci do swojego komputera. Rytm prac narzucać jednak będzie nie stały odcinek czasu nazywany sprintem, a moc obliczeniowa chmury. Gdy spłyną rozwiązania, warto się spotkać i je omówić, gdy nadal będą trwały obliczenia oraz automatyczne programowanie, trzeba poczekać. Czas będzie zdeterminowany mocą obliczeniową komputerów.
Skoro czas zależy od mocy obliczeniowej, to od czego zależy budżet projektu. Po stronie ludzkiej zamiast 50 programistów mamy 3 analityków. Więc te koszty stają się mniej istotne. To, co staje się istotne, to koszt obliczeń. Podejrzewam, że wzrośnie rola megacentrów danych, które będą obsługiwały tysiące projektów. I największym kosztem będzie dostęp do ich mocy. Chcesz mieć szybko innowacyjny system, grę mobilną, usługę? Zapłać dużo. Nie masz wystarczająco budżetu, poczekaj na wolne moce. A w tym czasie ci bogatsi zrealizują swoje koncepcje.
 Czym w takim razie zajmuje się kierownik projektu?
Czym w takim razie zajmuje się kierownik projektu?
Ponieważ wieszczę (autoironia zamierzona), że zespoły będą dużo mniejsze, to kompetencji społecznych potrzeba będzie dużo mniej. Natomiast wzrośnie rola tworzenia właściwej wizji i wskazywania obiecujących kierunków. Zatem raczej rola kierownika projektów będzie łączona z rolą product menadżera / wizjonera / menedżera liniowego. Po prostu menadżer biznesowy dobierze sobie zespół analityków/prompterów, którzy zrealizują jego marzenie.
I w tym miejscu pojawia się ciekawy obszar problemowy. Ale dla porządku cofnijmy się do wstępu tego artykułu. Dysponujemy dzisiaj czterema podejściami do zarządzania projektami. Rozwój możliwości technicznych może sprowokować do pojawienia się piątego podejścia. Podejścia opartego na wizji, prowadzącego do gwałtownych przełomów. Takie podejście musiałoby skupić się też na obszarach, które rozwijają się daleko wolnie, tu postęp mierzony jest dekadami, czyli w obszarze ludzkich postaw i mindsetu. Krótko mówiąc, skupiłoby się na polityce.
Przykład z przeszłości dobrze to ilustruje. Londyńska Giełda kilkadziesiąt lat temu miała wizję stworzenia systemu do digitalizacji obrotu akcjami – Taurus. Projekt miał trwać rok i przynieść spektakularny sukces. Skończył się po 10 latach totalną klapą i przekroczenie budżetu 37 razy. Jedną z przyczyn było pełzanie zakresu wynikające z niedogadania się z bankami oraz niedocenienie skali rozwiązania.
A teraz co by było, gdyby ten Taurus powstawał w 2035 roku. Zespół czterech analityków w kilka dni opisałby koncepcję przekazaną przez prezesa giełdy. Po dwóch tygodniach 10 wersji systemu byłoby gotowych wraz z oceną ich użyteczności oraz analizą koniecznych zmian w otaczających systemach. Banki znów zaczęłyby sabotować Taurusa, wprowadzając żądania zmian. Jednak prezes giełdy dokupiwszy moc obliczeniową, zacząłby z zespołem generować 20 równoległych wersji systemu, aby odpowiedzieć na te zmiany. Jego głównym zmartwieniem byłoby to, że banki tak powoli odpowiadają na prezentowane warianty rozwiązań. Im więcej zmian interesariusze by zgłaszali, tym więcej mocy trzeba dokupić, aby utrzymać tempo prac. Po raz pierwszy w historii ludzkości czas stałby się niemal całkowicie wymienny na pieniądze. Jedynym progiem nie do przejścia, byłby ludzki opór przed zmianą.
Budowanie przewagi polegać będzie na tym, że wizjoner danego rozwiązania potrafi trafniej wskazać, co warto rozwijać i jak przejść przez las wariantów. Wariantów generowanych automatycznie, jak opisałem wyżej. A następnie ów wizjoner skutecznie przekona odbiorców do korzystania z nowego rozwiązania, zdobędzie ich atencję. Masz dobry pomysł i pieniądze, możesz go natychmiast zbudować i sprawdzić. Chwilę później okaże się, czy pomysł był faktycznie dobry i czy nie przepaliłeś w tydzień wszystkich pieniędzy. Zaryzykuję tezę, że nie będzie liderów projektów nie będących jednocześnie merytorycznymi w obszarze tworzonego rozwiązania.
Podsumowanie
Jak wskazuje wielu futurologów, zawody, które się bronią dotyczą interakcji międzyludzkich (wielu woli pogadać z fryzjerem lub pójść do ludzkiej kasy), działań kreatywnych (LLM są kreatywne tylko na tyle, na ile znajdą kreatywny pomysł w swoich zbiorach danych), manipulacji rękami (trudno mi powiedzieć, kiedy roboty będą równie sprawnie co ludzie zachowywały się w zmiennym środowisku).
Jednak wszędzie, gdzie na wejściu jest informacja i na wyjściu ma być wygenerowana inna informacja, a samo przetwarzanie informacji opiera się na gigantycznych zbiorach analogicznych przetworzeń (zbiory uczące), tam nastąpi przełom. Zaowocuje on wzrostem skali działania i konwersją czasu na koszty przede wszystkim obliczeń.
Powyższe rozważania mają charakter spekulacyjny i są hipotetycznym scenariuszem. Spisałem je porwany romantyzmem atmosfery rozwoju AI w ostatnich miesiącach. Nikt nie wie, co się wydarzy i kiedy zbudujemy kolonie na Tytanie albo zetrzemy siebie samych z powierzchni Ziemii, albo jedno i drugie.
Obrazki wygenerowane przez AI rzecz jasna (https://openart.ai/create)

