


Bariery zarządzania wiedzą
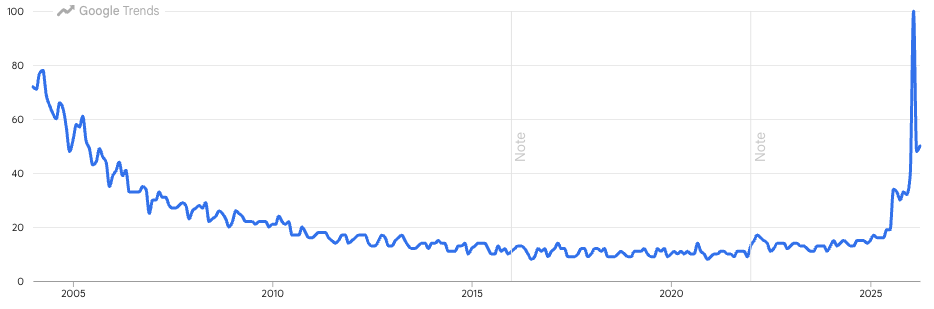
Gen AI zmienia różne obszary pracy, w tym zarządzanie wiedzą KM. Zmienia, redukując bariery technologiczne wytwarzania wiedzy i dostępu do niej. W tym artykule skupię się na wiedzy zewnętrznej, czyli takiej, która otacza organizacje. Tytułowy wykres pokazuje, jak zmieniało się zainteresowanie hasłem knowledge management na świecie na przestrzeni ostatnich 20 lat.
Bariery, które dotąd bardzo ograniczały wdrażanie KM można podzielić na techniczne i ludzkie:
Dzisiaj wydaje się, że dzięki LLM te techniczne redukowane są do zera. Potrafimy przeszukiwać duże zbiory nieustrukturalizowanych treści za pomocą mechanizmu embeddings, oraz generować gotowe odpowiedzi z użyciem LLM. Potrafimy nawet wywołać polecenia w trakcie rozmowy z czatem, aby otrzymać wiarygodne dane z bazy. Pozostają bariery ludzkie, ale mamy już połowę sukcesu.
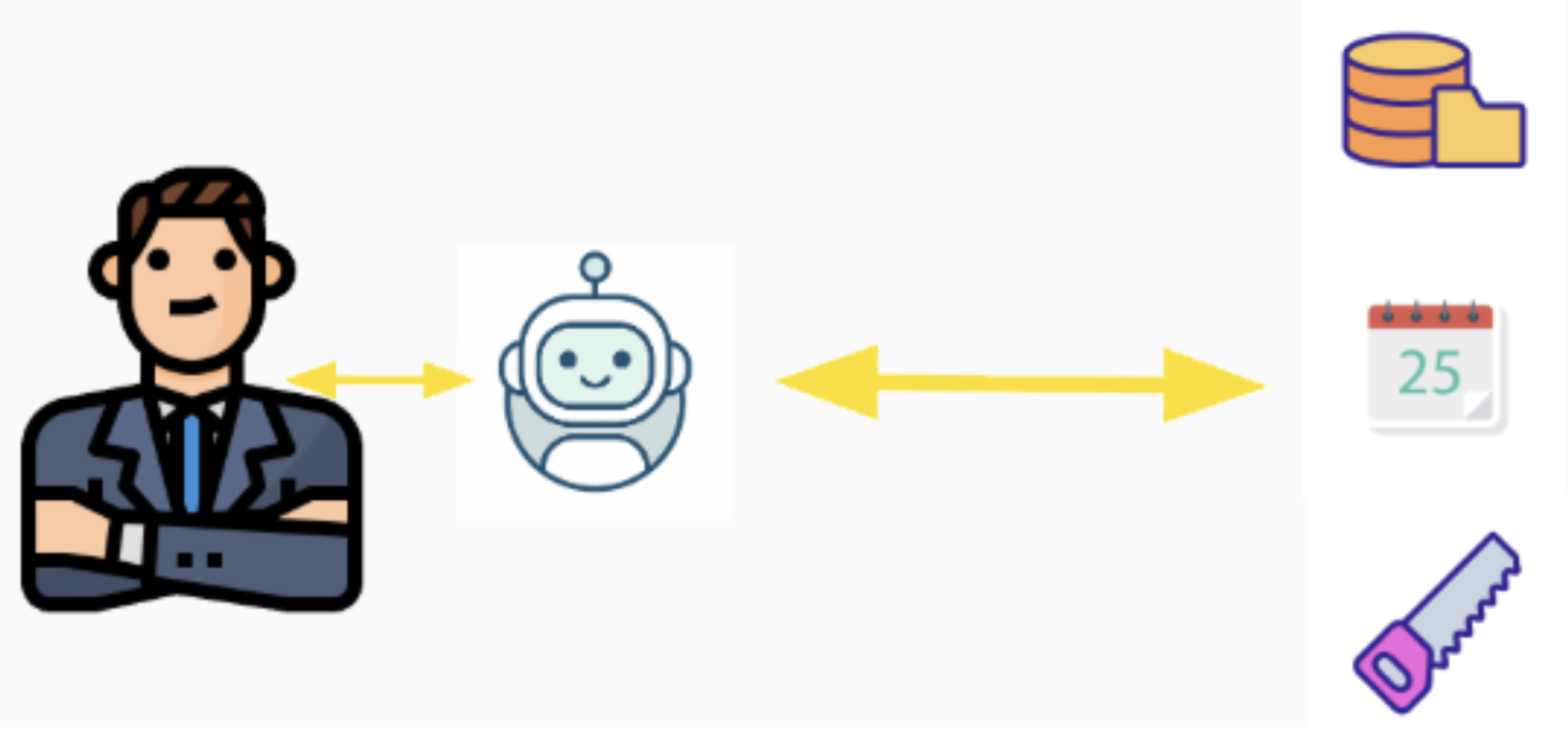
Niektóre profesje potrzebuję dostępu do wiedzy, która znajduje się poza organizacją. Im więcej tej wiedzy mają, tym są bardziej efektywne w swoje pracy. Przykłady można tu rzucać z odległych dziedzin, od maklerów na giełdach, przez produktowców, przez twórców kreatywnych treści, po naukowców i inwestorów. Każda z takich profesji potrzebuje regularnie zasilać się wiedzą, której wewnątrz po prostu nie ma.
Transfer wiedzy
Dotychczasowy proces konsumowania wiedzy zewnętrznej wyglądał mniej więcej tak:
Dzisiaj ten proces się zmienia. I moim zdaniem nie chodzi tylko o to, że wyszukiwanie semantyczne wspiera znajdywanie informacji, LLM podsumowuje długie teksty, a RAG serwuje precyzyjną informację pod konkretne, wąskie potrzeby. Chodzi mi o to, że zmienia się cały warsztat pracy pracownika wiedzy.
Podstawowym interfejs może być edytor Code, jak to pokazano poniżej z czatem z agentami AI. Po jednej stronie ekranu są pliki programu, a po drugiej ekrany czatów z wieloma agentami równolegle. Człowiek rozmawia, ale też wywołuje predefiniowane polecenia, które są zgodne z firmową metodyką.
Może to też być predefiniowane narzędzie z czatem takie, jak Didascal. Akurat Didascal zaprojektowany jest pod analizy na podstawie danych z internetu i mediów społecznościowych na różne tematy.

Taką platformą może też stać się czat na Anthropic, Perplexity, czy Copilot 5.0. Ważne, że w tle rozmów wiedza cały czas odkłada się przy okazji. Intencją organizacji jest archiwizować maksymalnie dużo wiedzy pracowników. Im bardziej będzie to odbywało się przy okazji innych zadań, bez dodatkowego wysiłku, tym lepiej. Super, gdyby udało się stworzyć filtr między umysłem pracownika a jego otoczeniem, który będzie odsiewał odkrywcze wnioski i je zapisywał. I taką rolę może pełnić właśnie czat AI wsparty: narzędziami + pamięcią + RAG.
A teraz wyobraźmy sobie wielu pracowników wiedzy korzystających ze swoich czatów do wykonywania zadań. Część z nich pisze specyfikacje i koordynuje tworzenie systemów informatycznych. Część z nich zajmuje się zarządzaniem produktem i gromadzi wiedzę z rynku oraz statystyk po to, aby planować eksperymenty. Zaś inni obsługują klientów, odpowiadają na reklamacje, wszystko za pośrednictwem czatów. Różnych czatów, róznie ustawionych, ale nadal wszystko przepływa przez AI. Metaforycznie taką sytuację pokazuje poniższy obrazek.
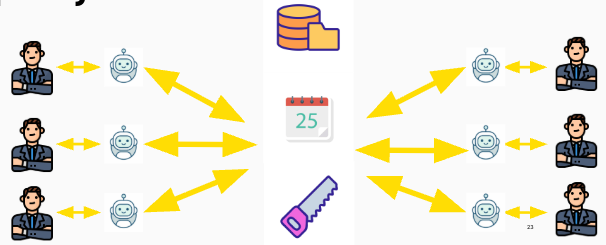
Każdy pracownik rozmawia ze swoim interfejsem, ten zaś pamięta jego kontekst, preferencje, styl komunikacji, założenia poczynione wcześniej stan poszczególnych zadań itd. W efekcie proste zadania mogą być negocjowane między agentami z pominięciem pracowników. Na przykład uzgodnienie terminu spotkania, albo rozdzielenie prac, ale wzajemna weryfikacja postępu zakresu.
A teraz wyobraźmy sobie jeszcze jeden wymiar: metodyki, architektury i governance. Dla uproszczenia wrzucę te aspekty do jednego work pod nazwą 'standardy'. Ktoś ponad pracownikiem może ustanowić standardy pracy, na przykład dla handlowca standardy przygotowania ofert z perspektywy prawnej, handlowej, produktowej, komunikacyjnej. Albo dla pracownika call center z perspektywy produktowej, skryptów rozmów, compliance, celów sprzedażowych. Albo dla product managera z perspektywy prawnej, wiarygodności eksperymentów i wniosków, trendów na rynku, strategii firmy, metodyki pracy. Albo dla urzędznika z perspektywy prawnej, wewnętrznych regulacji, zasad komunikacji. Tak skonfigurowane środowisko przestaje być spersonalizowanym czatem, a staje się wdrożonym procesem biznesowym.
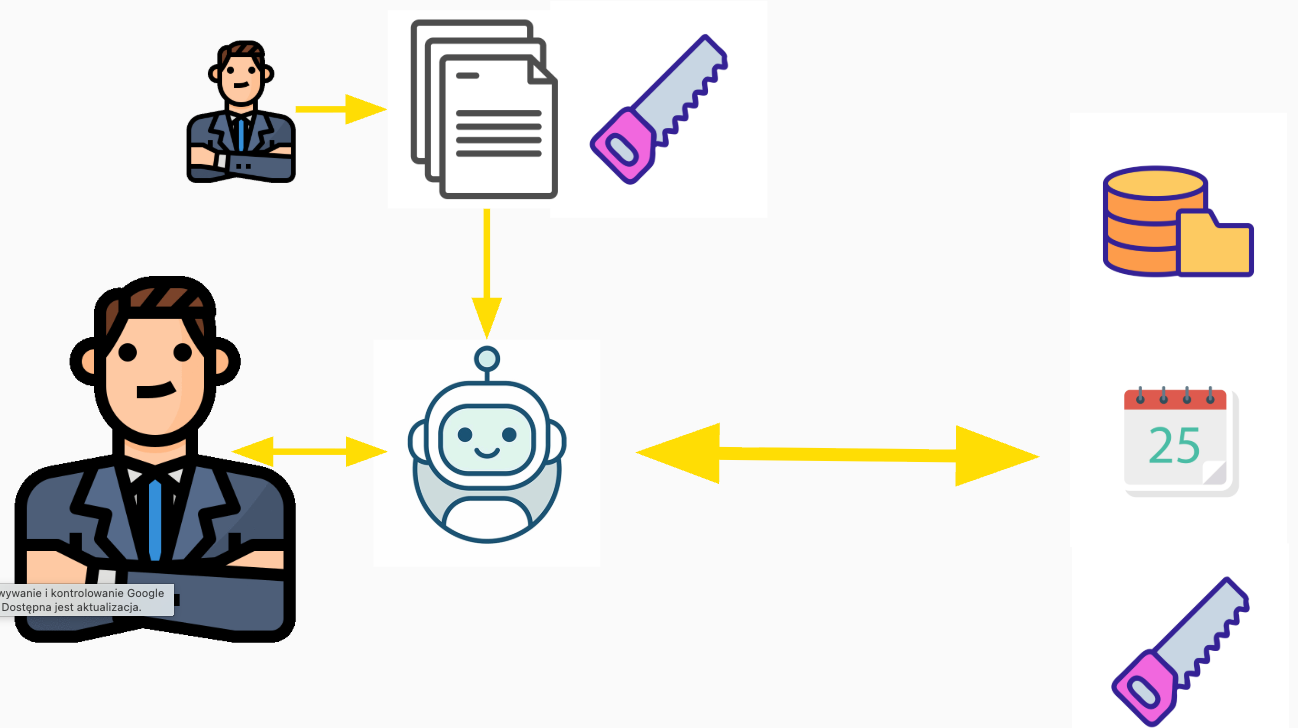
Podkreślę to, aby mocniej wybrzmiało. To czat odpowiada za utrzymanie pracownika w ryzach wykonywanego procesu. Pracownik dostarcza wiedzę, inwencję twórczą, zapał, skupia się na różnych priorytetach według własnego wyczucia, ale to czat sformatowany standardami prowadzi go po ścieżce, którą wybrała firma.
Na powyższym obrazku pracę nadzorują standardy tworzone przez kogoś wyżej: szefa, architekta, analityka. Co więcej inny LLM może odpowiadać za regularny, automatyczny audyt spełnienia standardów przez pracownika i generować raport odchyleń.
Oprócz standardów pracownik otrzymuje zestaw narzędzi z nimi powiązanych. Przykładowo w Spec Kit mamy narzędzia uruchamiające walidację specyfikacji, przygotowanie testów, zaplanowanie zadań, czy uruchomienie implementacji. Z reguły wywołanie narzędzia na poziomie technicznym oznacza uruchomienie predefiniowanego prompta albo serii promptów. Te narzędzia mają za zadanie prowadzić pracownika za rękę przez kroki procesu albo metodyki pracy.
Wróćmy do wymiary zarządzania wiedzą. Jak widać gromadzenie i przetwarzanie wiedzy staje się nierozerwalnie związane z wykonywaniem pracy. Realizując zadania, gromadzimy w bazie wiedzę, korzystając z wiedzy, robimy zadania. Raz na jakiś czas ktoś porządkuje nowe doświadczenia za pomocą aktualizacji standardów i sprzątaniem bazy wiedzy. W bazie pojawia się coraz więcej nieustrukturalizowanej wiedzy w postaci wątków dyskusyjnych, komentarzy, plików, ściągniętych stron z internetu, raportów itd.
Wątkiem wymagającym osobnego artykułu jest dryf modelu oraz koszt tokenów. Pewnie kiedyś go też poruszę. Natomiast przejdę teraz do kolejnej kwestii strukturalizacji.
Strukturalizacja wiedzy
Dotychczasowe rozważania dotyczyły wnioskowania jakościowego. Dzięki LLM jest to dziś dość proste, choć ma szereg słabości, jak nieostrość odpowiedzi, niska efektywność wnioskowania, brak jednoznacznego odróżnienia prawdy od fałszu, czy po prostu halucynacje. LLM umożliwiają jednak przejście na wyższy poziom, czyli strukturalizację wiedzy.
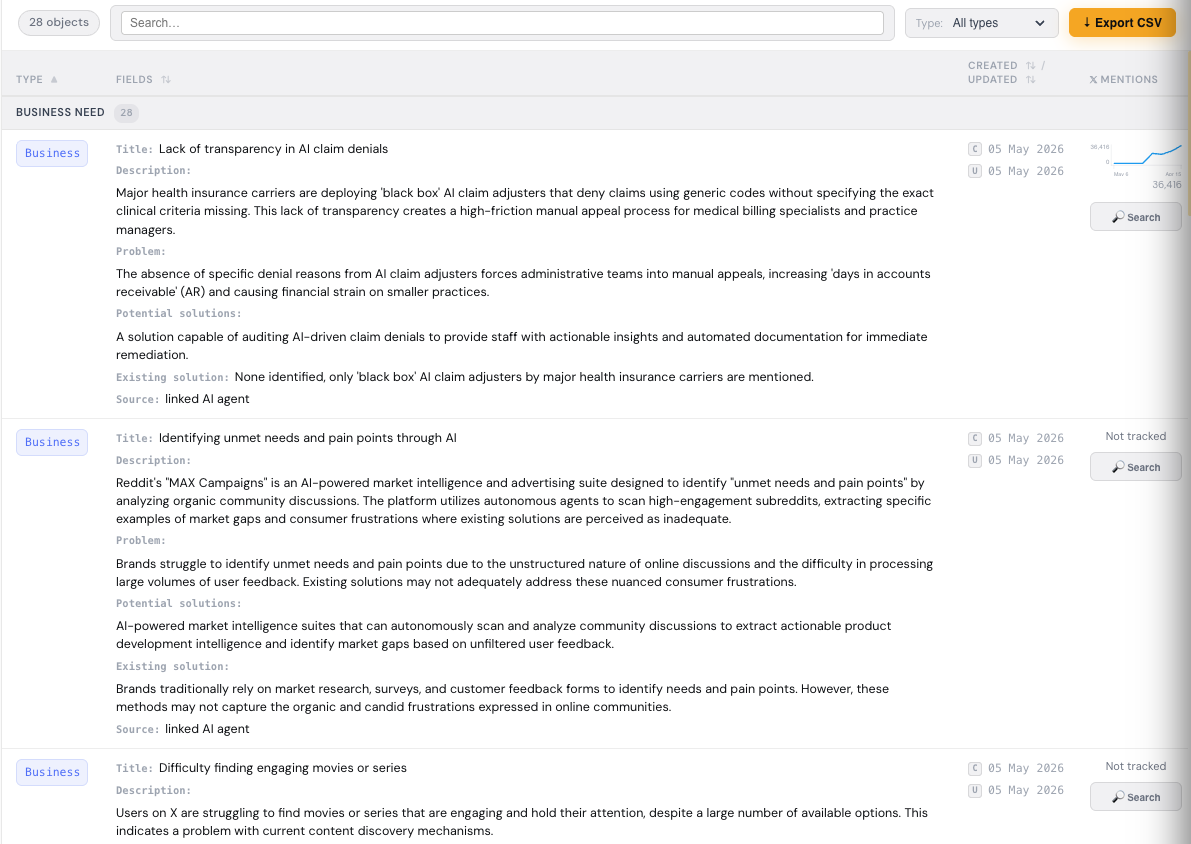
Takim przykładem gromadzenia wiedzy z platform społecznościowych, następnie jej ekstrakcji, i zamiany na formę ustrukturalizowaną (tabelę), a następnie śledzenie popularności wybranych obiektów tej tabeli jest to zestawienie Obiekty zidentyfikowane przez Didascal. Zadanie, jakie postawiłem w powyższym przykładzie to znajdowanie biznesowych problemów klientów, na które nie mogą znaleźć rozwiązań, źródłem jest Reddit i Twitter. Tabela się samoczynnie aktualizuje raz dziennie, o ile wpadną nowe informacje. A raz na tydzień uzupełniany jest wykres trendów komentarzy z Twittera. Po pierwsze użytkownik otrzymuje tabelę zamiast tekstu językiem naturalnym z predefiniowaną listą pól, a po drugie każdy wiersz tabeli uzyskuje tożsamość na podstawie wybranych kluczowych pól i można do niego przypinać dane ilościowe, np. trendy komentarzy na Twitter.
Wyobrażam sobie, że dopiero zamiana luźnych treści na zestawy tabel z obiektami i relacjami między nimi dokona prawdziwego przełomu w aspekcie gromadzenia i wykorzystania wiedzy. Wyobraźcie sobie firmę ecommerce, która ma dane całej konkurencji na świecie z trendami cenowymi. Ma też opinie klientów o konkurencji - 10 milionów anonimowych osób z internetu komentujących produkty konkurencji. Przecież te dane tam są. Analogicznie wyobraźcie sobie analityków inwestycyjnych, którym agenci AI najpierw budują bazę wiadomości ze wszystkich rynków świata, następnie przypinają te wiadomości do firm obecnych na giełdzie. Dodatkowo budują bazę ludzi: prezesów, inwestorów, polityków, powiazanych z tymi firmami. Następnie podpinają do tego dane kursów akcji i dane finansowe. Wreszcie znajdują relacje między spółkami a innymi spółkami, kto w kogo zainwestował, kto komu wykonuje projekt, kto z kim ma spór prawny. To jest prawdziwa baza wiedzy.
Jedną ze słabości LLM jest brak transparentnego wnioskowania na bazie zdań logicznych. To oznacza duże ryzyko kłamania i odpowiedzi typu to zależy. Człowiek zaś świetnie radzi sobie z takim typem wnioskowania. Kiedyś mówiło się o ontologiach w zarządzaniu wiedzą. Ten temat wydaje się powoli wracać i strukturalizacja obiektów na podstawie tekstów, jest moim zdaniem krokiem w tym kierunku.
Podsumowanie
Zarządzanie wiedzą przechodzi od sytuacji, gdy pracownik musiał w odrębnym zadaniu wyekstrahować swoją wiedzę do bazy w postaci odpowiedzi na pytanie lub artykułu, albo filmu, do sytuacji, gdy dzieje się ono przy okazji wykonania zadania. Wprowadzenie pośrednika w postaci agentów AI powoduje, że z każdą operacją, każdym komentarzem wiedza odkłada się bez kosztowo dla człowieka.
To, z czym organizacje muszą sobie poradzić, to:


 szkolenia@octigo.pl
szkolenia@octigo.pl +48 512 364 075
+48 512 364 075 Redycka 38/1, 51-169 Wrocław, Poland
Redycka 38/1, 51-169 Wrocław, Poland