


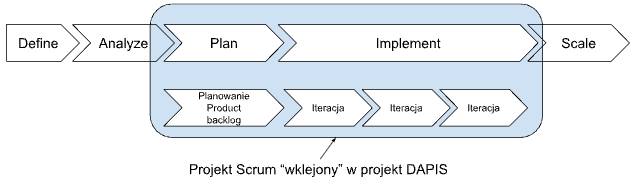
Faza Plan w metodyce DAPIS – jak zaplanować projekt LLM, żeby nie spalić budżetu
Seria: Wdrażanie AI w organizacji krok po kroku
Projekty oparte na dużych modelach językowych (LLM) mają jedną nieprzyjemną cechę wspólną: potrafią wyglądać obiecująco na etapie pomysłu, a potem albo przekroczyć budżet trzykrotnie, albo dostarczyć wynik, którego nikt nie chce użyć. Faza Plan w metodyce DAPIS ma temu zapobiec. To etap, który odpowiada na jedno zasadnicze pytanie: W JAKI SPOSÓB?
Celem jest stworzenie wiarygodnego, uzgodnionego z uczestnikami planu wdrożenia. Etap kończy się formalnym potwierdzeniem przez sponsora zakresu, terminów i ram budżetowych. Dopiero wtedy ruszamy z robotą.
Trzy wymiary planu
Każdy plan w DAPIS opiera się na trzech filarach: zakresie, czasie i koszcie. Do tego dochodzi czwarty, często pomijany wymiar – regulacje prawne. Omówmy każdy z nich.
1. Zakres – co zamierzamy zrobić
Zakres to lista przedmiotów dostaw i zadań potrzebnych do ich stworzenia. Warto uzupełnić ją o wyłączenia – rzeczy, których świadomie nie robimy w tym projekcie. Pozwala to uniknąć późniejszych nieporozumień z interesariuszami.
Zapis zakresu może przyjąć formę:
- product backlogu – lista wymagań funkcjonalnych posortowana według ważności (podejście zwinne),
- WBS (Work Breakdown Structure) – hierarchia produktów i zadań (podejście kaskadowe).
Wykonalność to nie oczywistość
Zanim zaczniesz planować szczegóły, sprawdź, co organizacja w ogóle dopuszcza. Jedna firma może zezwalać wyłącznie na korzystanie z gotowego interfejsu Copilot bez możliwości załączania plików. Inna może mieć zablokowane API zewnętrznych modeli. Jeśli twój pomysł zderza się z tymi ograniczeniami, lepiej wiedzieć o tym w fazie Plan, a nie po dwóch miesiącach pracy.
Benchmark – jak zmierzysz sukces
To jeden z ważniejszych elementów zakresu, a jednocześnie najczęściej pomijany. Benchmark to zdefiniowana procedura pomiaru jakości działania modelu w konkretnym kontekście. Nie istnieje jeden uniwersalny benchmark – każdy projekt wymaga własnego.
Typowe pytania, na które benchmark powinien odpowiadać:
- Czy model nie generuje treści obraźliwych lub niezgodnych z prawem?
- Czy nie ujawnia danych wrażliwych?
- Czy odnosi się do wszystkich kwestii zawartych w zapytaniu?
- Czy nie halucynuje – nie podaje błędnych informacji o ofercie lub procesie?
- Czy poprawnie odczytuje i przelicza wartości liczbowe?
- Czy trafnie kategoryzuje analizowane treści?
Zbiór testowy powinien liczyć co najmniej 20 rekordów reprezentujących realne dane z procesu. Do każdego rekordu przypisujemy wzorcową odpowiedź, a następnie wybieramy metodę oceny:
- Zgodność z wzorcem – odpowiedź musi być identyczna z oczekiwaną (dobre przy generowaniu JSON, ekstrakcji wartości).
- Spełnienie kryteriów – liczymy, ile wymaganych elementów znalazł model (dobre przy odpowiedziach otwartych, streszczeniach).
- Ocena ludzka – gruppe osób subiektywnie ocenia odpowiedzi, np. pod kątem uprzejmości i precyzji (dobre przy chatbotach obsługowych).
- Ocena przez LLM – droższy model ocenia tańszy; skalowalny, ale wymaga ostrożności wobec błędów sędziego.
Procedurę benchmarku zwykle iteruje się kilkakrotnie. Przy pierwszym podejściu często okazuje się, że prompt był niedoprecyzowany i wyniki są niejednoznaczne – to normalne.
2. Czas – kiedy to zrobimy
W projekcie LLM wystarczy podzielić prace na etapy i ustalić daty końca każdego z nich. Harmonogram powinien obowiązkowo uwzględniać dwa elementy:
Proof of Concept (PoC)
PoC to szybka, ręczna demonstracja, że fragmenty rozwiązania mogą działać. Zanim zbudujesz system do odpowiadania na reklamacje, wklej kilka przykładowych zgłoszeń do Copilota lub GPT i sprawdź, co wychodzi. Jeśli odpowiedzi wyglądają sensownie – pokaż je interesariuszom. Jeśli model generuje bzdury od razu – popracuj dłużej nad promptem lub rozważ rezygnację z projektu.
PoC nie wymaga budowania finalnego rozwiązania. To celowe.
Pilotaż
Pilotaż to już działające rozwiązanie, ale uruchomione w ograniczonej skali. Klasyczny przykład: prosta strona WWW z formularzem w wewnętrznej sieci, bez logowania, z jednym przetestowanym promptem. Taki pilot można postawić w kilka dni. Przesuwa wyzwanie z pytania „czy to w ogóle działa?' na pytanie „co robimy z wynikami?' – a to zupełnie inna, lepsza rozmowa.
Złota zasada: typowy projekt LLM nie powinien trwać dłużej niż 3 miesiące. Przy większym zakresie lepiej podzielić go na kilka mniejszych projektów.
3. Koszt – ile to będzie kosztować
Koszty projektu LLM dzielą się na trzy kategorie:
- praca ludzi (mierzona w osobodniach),
- zakupy niezbędne do realizacji projektu,
- koszty operacyjne po wdrożeniu (m.in. tokeny).
Jak obliczyć rentowność
Rentowność projektu wylicza się przez porównanie dwóch równań:
Dzisiejsze koszty procesu (miesięcznie):
C × P × K
gdzie: C = liczba cykli procesu, P = pracochłonność jednego cyklu, K = koszt pracownika na jednostkę czasu.
Docelowe koszty procesu (miesięcznie):
C × (P' × K + LLM)
gdzie: P' = pracochłonność po wsparciu przez LLM (może spaść do zera przy pełnej automatyzacji), LLM = koszt tokenów na jeden cykl.
Jeśli wynik dzisiejszych kosztów podzielony przez docelowe jest większy od 1 – projekt przyniesie finansową korzyść. Poniżej 1 – warto zastanowić się, czy istnieją inne uzasadnienia (jakość, szybkość, satysfakcja klienta).
Uwaga na tokeny
Koszty tokenów potrafią zaskoczyć. Przy prostych promptach i małych modelach to może być grosz za zapytanie. Przy wielokrokowych łańcuchach myśli z największym modelem – kilkadziesiąt złotych za jedno zapytanie. Środowiska agentowe zużywają szacunkowo czterokrotnie więcej tokenów niż zwykły czat.
Przykładowe dwie metody optymalizacji kosztów wykorzystania LLM:
- RAG (Retrieval-Augmented Generation) – zamiast przesyłać cały dokument, model dostaje tylko semantycznie dopasowane fragmenty.
- Dobór modelu do zadania – nie każde zadanie wymaga największego modelu. Mniejsze modele są tańsze i szybsze. Testy jakości pozwalają ustalić optymalny dobór dla każdego kroku w procesie.
4. Regulacje – o czym łatwo zapomnieć
Wymiar prawny często pojawia się dopiero gdy jest problem. W DAPIS pojawia się już w fazie Plan. Cztery obszary wymagają uwagi:
- Poufność: jeśli LLM ma dostęp do jakiejś informacji, można ją wyciągnąć odpowiednio skonstruowanym promptem. Jedyna pewna strategia: nie umieszczać wrażliwych danych w zasobach modelu.
- Mylna informacja: model może przedstawić błędną rekomendację lub cenę, którą użytkownik potraktuje jako wiążącą. Przykład: chatbot, który po krótkiej rozmowie zgodził się udzielić 90% rabatu.
- Bezpieczeństwo reputacji: jeden zrzut ekranu z nieodpowiednią odpowiedzią modelu może wylądować w mediach społecznościowych i stać się memem. W przypadku rozpoznawalnych marek – szybko.
- RODO i AI Act: modele dotrenowane na danych firmowych mogą niezamierzenie przechowywać dane osobowe. Żądanie usunięcia takich danych przez osobę fizyczną może oznaczać konieczność ponownego trenowania modelu – co jest bardzo kosztowne.
Zatwierdzenia i pytania kontrolne
Ostatnim krokiem fazy Plan jest uzyskanie formalnych zatwierdzeń od sponsora projektu oraz jednostek odpowiedzialnych za jakość, zgodność z prawem i bezpieczeństwo. Dobrą praktyką jest stworzenie instytucjonalnej listy kontrolnej – kto musi podpisać plan przed rozpoczęciem wdrożenia.
Przed zamknięciem fazy warto odpowiedzieć na kilka pytań:
- Na czym polegają konkretne korzyści z wdrożenia – oszczędności czasu, redukcja błędów, lepsza obsługa klienta?
- W jaki sposób będziemy mierzyć jakość działania komponentu AI?
- Jaki minimalny poziom jakości LLM (brak halucynacji, odporność na manipulację) jest wymagany do dopuszczenia rozwiązania do użytku?
- Z jakich modułów składa się projektowane rozwiązanie?
- Jakie są etapy i prognozowane daty ich zakończenia?
- Co trzeba zakupić i jakie będą koszty operacyjne po wdrożeniu?
- Jakie ryzyka prawne, biznesowe i reputacyjne wiążą się z projektem?
Wpis oparty na materiałach metodyki DAPIS dotyczących wdrażania rozwiązań opartych na LLM w środowiskach biznesowych.


 szkolenia@octigo.pl
szkolenia@octigo.pl +48 512 364 075
+48 512 364 075 Redycka 38/1, 51-169 Wrocław, Poland
Redycka 38/1, 51-169 Wrocław, Poland