



 Jednym z głównych powodów, dlaczego zarządzanie wiedzą słabo działa w organizacjach jest koszt. Z jednej strony jest to koszt dodawania nowej wiedzy korporacyjnych baz, a z drugiej strony jest to koszt wyszukiwania wiedzy w tychże bazach skutkujący racjonalną ignorancją.
Jednym z głównych powodów, dlaczego zarządzanie wiedzą słabo działa w organizacjach jest koszt. Z jednej strony jest to koszt dodawania nowej wiedzy korporacyjnych baz, a z drugiej strony jest to koszt wyszukiwania wiedzy w tychże bazach skutkujący racjonalną ignorancją.
Pracownik, który ma dodać wiedzę, musi ją odpowiednio zredagować, skatalogować, dodać tagi, dodać informację o zakresie obowiązywania, np. w jakich terminach wiedza nadal jest aktualna, upewnić się, czy w treści zawarto słowa kluczowe, które pozwolą na późniejsze wyszukanie. Na to nakłada się zjawisko racjonalizacji wysiłku. Jeżeli mało kto szuka w bazie wiedzy i korzysta z wprowadzonych materiałów, to po co tracić czas i wrzucać tam swoje treści.
Artykuł jest fragmentem książki Bardziej niż Agile będącej w trakcie druku: https://onepress.pl/ksiazki/bardziej-niz-agile-marcin-zmigrodzki,baragi.htm#format/d
Pracownik, który wiedzę wyszukuje musi wpisać właściwe zapytanie. Przewijać listę znalezionych dokumentów, aby natrafić na użyteczny. Czasem ponownie wpisać zapytanie, gdy nic nie znajdzie. W efekcie może włączyć się mu syndrom racjonalnej ignorancji. To sytuacja, gdy racjonalniej jest nie poszukiwać nowej wiedzy, bo koszt z tym związany pomnożony przez spodziewaną szansę na znalezienie czegoś użytecznego jest wyższy niż wartość z tej wiedzy. Innymi słowy pracownik może sobie pomyśleć, po co będę grzebał w bazie wiedzy, skoro i tak nic tam nie ma. Łatwiej jest ominąć bazę wiedzy i zadzwonić do kolegi, który chyba się zna.
W wyniku działania tych dwóch postaw, bazy wiedzy są puste, albo zawierają bezwartościowe informacje i mało kto do nich zagląda. Utrzymanie ich jest kosztowne, więc organizacjom taniej jest z nich zrezygnować.
Tak wyglądała sytuacja na początku XXI wieku, gdy wspólnie z kolegami wymyśliliśmy i wypuściliśmy na rynek pierwszy polski system zarządzania wiedzą Pyton. Technicznie fantastyczne narzędzie, które wykorzystywało algorytmy analizy języka naturalnego, biznesowo totalna klapa.
Jednak w 2022 roku na rynek weszły wielkie modele językowe (LLM - Large Language Models). Dzięki ich zaawansowaniu nie trzeba już szczegółowo opisywać dokumentów wrzucanych do bazy wiedzy, bowiem model może zrobić to za człowieka. Przykładowo może sam zaproponować tagi dokumentu. Wystarczy wkleić lub wczytać dokument i automat po chwili go udostępni do wyszukiwania. Wyszukiwanie również stało się dużo prostsze i skuteczniejsze. Można wręcz prowadzić rozmowę z własną bazą wiedzy tak, jakbyśmy zatrudnili sztucznego mentora. Wierzę, że dzięki zredkowaniu kosztu dodawania oraz wyszukiwania wiedzy popularność baz wiedzy gwałtownie wzrośnie. Wreszcie zaczną dostarczać wartość powyżej poziomu racjonalnej ignorancji.
Poniżej prezentuję schemat funkcjonowania architektury RAG na przykładzie mojej własnej bazy wiedzy, która powstała podczas pisania tej książki.
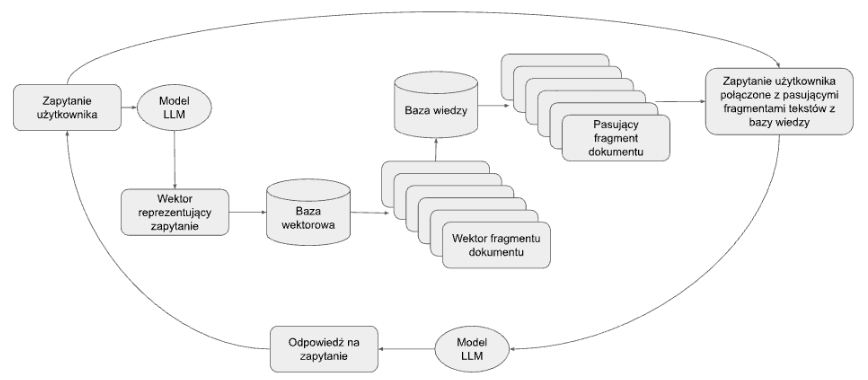
Rys. Schemat działania RAG.
Według powyższego rysunku użytkownik wchodzi do bazy wiedzy i zadaje pytanie językiem naturalnym, np. “Co wpływa na innowacyjność pracowników?”. System zamienia to zdanie na wektor, nazywany embeddingiem, czyli zbiór kilkuset wartości reprezentujący znaczenie niesione przez to zdanie. Ten wektor porównywany jest z innymi zapisanymi w bazie wektorami, które reprezentują dokumenty lub ich fragmenty z bazy wiedzy. W rezultacie baza wiedzy wyświetla listę dokumentów, które odpowiadają na pytanie użytkownika. Tak działa pierwszy krok RAG, czyli wyszukiwanie semantyczne. To wyszukiwanie daje sobie doskonale radę nawet, gdy zapytanie jest w języku mocno fleksyjnym takim, jak polski, a dokumenty w bazie są po angielsku.
W kroku drugim zapytanie użytkownika wraz z fragmentami z bazy wiedzy staje się promptem do modelu LLM (przykładowo GPT, Gemini, Claude, Mixtral, Spichlerz). W odpowiedzi LLM zaczyna rozmawiać z użytkownikiem. Przykład takiego dialogu w systemie Wroolo widać poniżej.
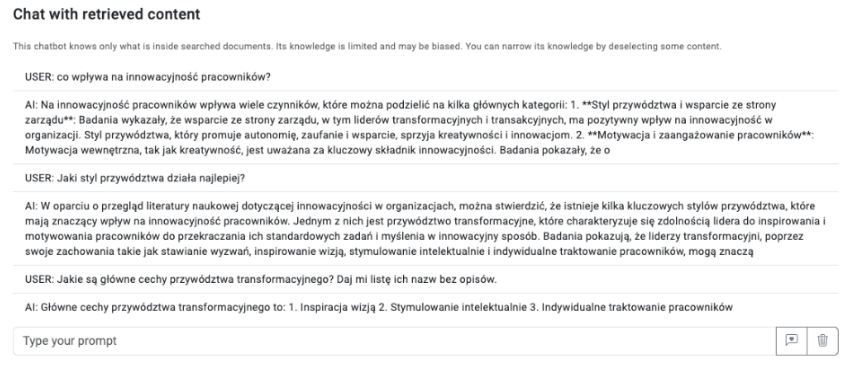
Rys. Przykładowy dialog z bazą wiedzy stworzoną we Wroolo na potrzeby pisania niniejszej książki.
W powyższej bazie wiedzy znalazło ponad dwieście dokumentów na temat innowacji w organizacjach, przywództwa, zarządzania projektami i wiele innych. Jak widać powyżej, gdy użytkownik zada pytanie, na które można znaleźć odpowiedź w bazie, rozpoczyna się dialog z algorytmem LLM. Przypomina on rozmowę z mentorem, ale tak naprawdę polega on na przetworzeniu tekstów, które semantycznie pasują do zapytań użytkownika.


 szkolenia@octigo.pl
szkolenia@octigo.pl +48 512 364 075
+48 512 364 075 Redycka 38/1, 51-169 Wrocław, Poland
Redycka 38/1, 51-169 Wrocław, Poland