Obserwuję od jakiegoś czasu techniki zarządzania projektami wykorzystywane przez biznes i porównuję je czasem do technik stosowanych w obszarze zarządzania procesami, a szczególnie procesami produkcyjnymi w dojrzałych fabrykach. I mam wrażenie, że jako kierownicy projektów jesteśmy na etapie dostrzeżenia, że obok piaskownicy, w której budujemy babki, za płotem stoją zaawansowane maszyny budowlane. I sobie myślimy, że gdyby użyć takiej koparki, to postawilibyśmy tysiące babek w godzinę. Więc zaczynamy stawiać babki w dużym tempie, gdy już prezes da nam budżet na nową koparkę. Po kilku tysiącach babek okazuje się jednak, że zarządowi chodziło raczej o postawienie biurowca, który podniósłby efektywność firmy.
Jednym z dobrych przykładów jest szacowanie kosztów projektu. PMBOK Guide ponad sto razy wymienia technikę Expert Judgment, która po polsku zwana bywa wróżeniem z fusów albo wystawianiem palca na wiatr, aby ustalić, jaka będzie pogoda. Aby zwiększyć rzetelność prognoz, warto zmienić perspektywę w dwóch obszarach. W trakcie pewnej konferencji rok temu uczestnicy mieli szansę usłyszeć od dostawcy analitycznego systemu, że metoda Monte Carlo jest odpowiedzią na ich problemy. Każdy projekt szacowany tą metodą zanotuje opóźni się mniej albo w mniejszym stopniu przekroczy przyznany budżet. Jednak po prezentacji wspaniałych funkcji padło pytanie, a skąd wziąć dane wejściowe do tej metody. Odpowiedź - Oszacować ekspercko. I bach, okazało się, że kolejna babka gotowa.
Szacowanie można dokonywać na różnych poziomach dojrzałości. Poniżej przygotowałem umowną hierarchię rzetelności szacunków:
- Szacować ekspercko. Jeden ekspert mówi, co mu się wydaje i przyjmujemy to za pewnik. Jedną z głównych wad tej metody jest niemożność oceny wiarygodności odpowiedzi eksperta. Czyli innymi słowy, ile jest eksperta w ekspercie.
- Szacować za pomocą grupy ekspertów, np. poker planning, mądrość tłumów, swarm intelligence. Wielu ekspertów mówi, co im się wydaje, ale potem patrzymy, jaki jest rozrzut ich odpowiedzi i omawiamy wyniki. Przy czym skupiamy się przede wszystkim na skrajnych odpowiedziach.
- Szacować na bazie analogii anegdotycznie. Kiedyś zdarzył się nam projekt, który był w terminie, więc i tym razem się uda. Dobrym przykładem takie myślenia jest historia Kanału Sueskiego, a następnie Kanału Panamskiego.
- Szacować na bazie analogii z wielu projektów. Zwykle projekty przekraczają budżet o 10%, więc i tym razem się uda.
- Szacowanie na podstawie danych statystycznych w punkt. Przykładowo: na podstawie dziesięciu ostatnich projektów możemy powiedzieć, że wdrożenie średnio trwa 2 miesiące.
- Szacowanie na podstawie danych statystycznych z uwzględnieniem prawdopodobieństwa. W tym wpisie chcemy zapoznać się właśnie z tym podejściem.
Po pierwsze wato oprzeć się na twardych danych historycznych, a nie na naszym odczuwaniu, stopnia w jakim przeżyte doświadczenia wywarły piętno na postrzeganiu przyszłości (tzw.
zjawisko kotwiczenia). Po drugie warto wyceniać przedziałowo z użyciem prawdopodobieństwa. W punkt trafić bardzo ciężko, np. stwierdzając, że projekt się skończy 31 grudnia, prawie na pewno się pomylimy. Gdy pomyłka będzie niewielka, zostanie zignorowana. Zawsze można ogłosić zakończenie 31 grudnia o 16:00, kiedy nikogo już nie ma w pracy, a potem wyjechać na urlop w góry be zasięgu. Następnie wrócić 8 stycznia do pracy i ze zdziwieniem oznajmić, że 31 grudnia wszystko działało i w ciągu kilku dni naprawić oczywiste pomyłki. Gdy pomyłka będzie większa, może przysporzyć sporych problemów. Wniosek, który może zostać w głowie po szacowaniu w punkt, to że projekty zawsze się spóźniają i przekraczają budżet, a ludzie kłamią. Jednak w zdobywaniu wiedzy o niepewności nie chodzi o to, aby od razu wszystko trafnie przewidywać. Chodzi o to, aby stopniowo redukować błąd. Wystarczy za każdym razem, gdy skończymy kolejny projekt powiększymy naszą wiedzę i zmniejszymy błąd estymacji, dajmy na to, o 3%. Już po piętnastu projektach nasz błąd estymacji będzie dwa razy mniejszy a to bardzo duży postęp.
Szacując w przedział jest dużo łatwiej trafić. Możemy stwierdzić, że najwcześniej skończymy 31 grudnia, a najpóźniej 29 lutego. Wówczas od razu widać, jak realny jest finał projektu jeszcze w tym roku. Pierwszą informację, jaką otrzymujemy to jak wiele nie wiemy o projekcie. Innymi słowy uzyskujemy informację o pewności naszych przewidywań. Gdy budżet projektu jest oszacowany na 90 do 120 tysięcy, to komunikujemy dużo większą pewność, niż, gdy szacujemy budżet na 60 do 150 tysięcy. Należy pamiętać, że pewność w dużym stopniu zależy od konstrukcji psychicznej eksperta. Bardzo pewni siebie eksperci mogą notorycznie się mylić i notorycznie podawać wąski przedział.
Aby podnieść wiarygodność estymowania warto jednak zrezygnować z prognoz podawanych przez ludzi, nawet w postaci przedziału. Warto zbierać faktyczne dane o wykonaniu prac i analizować je za pomocą statystyk. Przykładowo wyobraźmy sobie, że pytamy ile osobodni zajmie projekt nowej witryny internetowej. Nasz ekspert odpowie - 100 dni, bo dobrze pamięta ostatni projekt, w którym brał udział. Aby ładnie brzmiało zaokrąglił tą wycenę z 92 do 100. Pominął przy tym czas potrzebny na zebranie wymagań, bo ten go nie dotyczył. A także czas poświęcany na usuwanie błędów, ponieważ ten będzie jeszcze konsumowany przez kilka miesięcy od wdrożenia. Prezes na to odpowiada, że 100 to za dużo, bo on pamięta taki projekt, który był zrobiony w połowę tego czasu.
Krok 1.
Wyobraźmy sobie, że przez ostatni rok zbieraliśmy dane z różnych projektów wdrożenia witryn internetowych i okazało się, że fakty są takie:
| nr projektu |
liczba osobodni |
| 1 |
120 |
| 2 |
107 |
| 3 |
121 |
| 4 |
108 |
| 5 |
112 |
| 6 |
50 |
| 7 |
290 |
| 8 |
92 |
Okazuje się, że prezes ma racje. Był kiedyś projekt, który zajął 50 dni, jednak typowy projekt w firmie zajmuje nawet ok. 125 dni. Szkoda też, że prezes zapomniał o projekcie, który zajął 290 dni. Jeżeli firma planuje sobie marżę na poziomie 25%, to wycena na poziomie 100 dni grozi tym, że nic nie zarobimy na tym projekcie.
Krok 2.
Załóżmy, że mamy najważniejsze dane o naszych inwestycjach. I są to dane historyczne zebrane na bazie większej liczby projektów, czyli dość wiarygodne. W naszym kolejnym przykładzie mamy firmę transportową Koniczynka, która zastanawia się, jakie samochody kupić. Ma do wyboru sedany, limuzyny lub minivany. Dla uproszczenia rozważa zakup auta tylko jednego typu.
W trakcie burzy mózgów pracownicy firmy Koniczynka stworzyli model posiadania auta, który składa się z poniższych elementów:
- koszt miesięczny utrzymania auta - X1
- cena auta - X2 - przyjmuje się, że sedan i limuzyna mogą być wykorzystywane przez 5 lat, zaś minivany przez 7 lat.
- zysk na kursie rozumiany jako cena kursu minus koszt kursu - X3
- ilość kursów tygodniowo - X4
Do każdej z tych zmiennych (nazwijmy je iksami - X) firma posiada rzeczywiste dane z ostatnich kilku lat. Ustalono, że wzór na roczny dochód z auta wygląda tak: Y = (X3*X4*52) - (X1*12 + X2/liczba lat). To równanie w metodzie Monte Carlo nazywane jest równaniem transferowym.
Koszt utrzymania auta jest taki sam dla wszystkich wariantów i wynosi X1 = 500 zł. Cena, czyli X2, sedana wynosi 100 000 zł., minivana - 120 000 zł., limuzyny - 200 000 zł.
Po zebraniu danych okazało się, że X1, X3 i X4 wynoszą, jak poniżej:
| auto |
X3 - średni zysk na kursie |
X4 - średnia liczba kursów |
| sedan |
10 |
110 |
| minivan |
6 |
140 |
| limuzyna |
8 |
130 |
Po bliższej analizie danych historycznych wyszło na jaw, iż zmienne X3 i X4 mają różny rozkład. Poniżej zaprezentowano ich odchylenie standardowe.
| auto |
X3 - odchylenie st. |
X4 - odchylenie st. |
| sedan |
1 |
5 |
| minivan |
1,5 |
20 |
| limuzyna |
2 |
10 |
Uwaga samo dotarcie do tego, jaki rozkład najlepiej obrazuje zachowanie się zmiennej nie jest łatwe i wymaga wiedzy statystycznej. W najprostszym wariancie możemy przyjąć, że zmienna zachowuje się równomiernie losowo w zadanym zakresie wartości minimum / maksimum. W bardziej złożonym możemy przyjąć istnienie rozkładu trójkątnego minimum / średnia / maksimum. W jeszcze bardziej złożonym podejściu możemy przeprowadzić test statystyczny i ustalić faktyczny rozkład zmiennej. Z dużym uproszczeniem przyjmijmy dla potrzeb wywodu, że X3 oraz X4 mają rozkład równomierny z zadanym przedziale min / maks. Min = średnia - 3*odchylenie st., Max = średnia + 3*odchylenie st.
Zatem tabelka ze zmiennymi X3 i X4 wygląda następująco:
| auto |
X3 - min ... maks |
X4 - min ... maks |
| sedan |
7 ... 13 |
95 ... 125 |
| minivan |
1,5 ... 10,5 |
80 ... 200 |
| limuzyna |
2 ... 14 |
100 ... 160 |
Krok 3.
Teraz skoro mamy już wszystkie parametry wejściowe oraz równanie transferowe, możemy zająć się modelowaniem Monte Carlo. W tym celu tworzymy karty dla każdego wariantu decyzji, czyli karta sedana, minivana i limuzyny. Decyzję, którą rozważamy jest roczny zysk na posiadaniu auta danego typu. Dla karty sedana może to wyglądać tak
| auto |
X1 |
X2 |
X3 |
X4 |
Y |
| sedan |
koszt mies *12 |
cena / 5 lat |
=LOS.ZAKR(7;13) |
=LOS.ZAKR(95;125) |
Y = (X3*X4*52) - (X1*12 + X2/liczba lat) |
| sedan |
6000 |
20000 |
7 |
96 |
8944 |
| sedan |
6000 |
20000 |
9 |
120 |
30160 |
| sedan |
6000 |
20000 |
10 |
101 |
24500 |
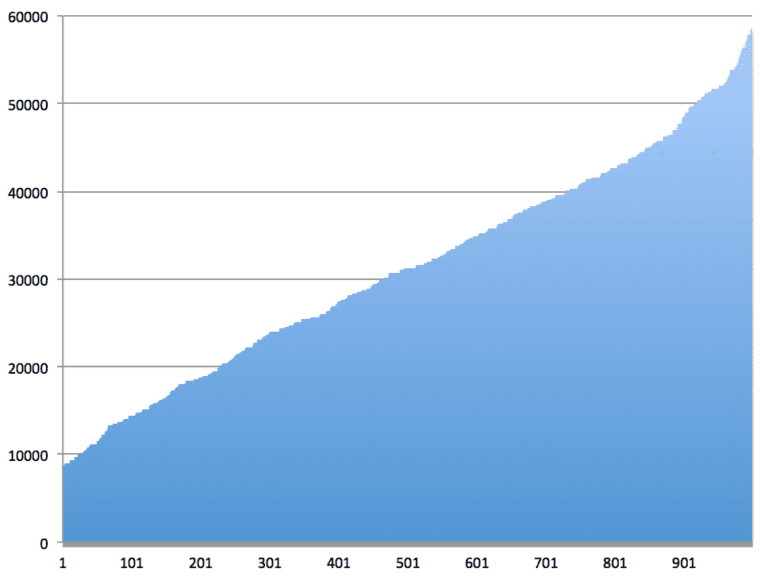
Przygotowawszy taki arkusz w Excel możemy wygenerować 10 000 wierszy z losowymi wartościami zmiennych X. W efekcie otrzymamy 10 000 losowych wartości zmiennej Y. Wystarczy teraz posortować Y rosnąco (w tym celu będziecie musieli skopiować kolumnę z Y przez wartość do innego arkusza i wtedy posortować) i spojrzeć na rozkład Y.
Z wykresu wynika, że na 50% zysk roczny z sedana wyniesie conajmniej 31200 zł., a na 80% - conajmniej 18772 zł. Zmienność w tym wypadku wynika z losowości liczby oraz zysku z kursów. Innymi słowy na 10 000 losowych scenariuszy wartość Y była w 8 000 większa niż 18772 zł. Na rysunku obok oś pozioma pokazuje scenariusze, oś pionowa to wartość Y.
Analogiczne kart należy stworzyć dla limuzyny i minivana. Przez porównanie wartości dla każdego z trzech typów aut uzyskamy odpowiedź, który wariant najbardziej się opłaca.
Obliczenie pozostałych dwóch wariantów pozostawiam jednak drogim czytelnikom.
Więcj o metodzie Monte Carlo możecie znaleźć na Wikipedii.





 szkolenia@octigo.pl
szkolenia@octigo.pl +48 512 364 075
+48 512 364 075 Redycka 38/1, 51-169 Wrocław, Poland
Redycka 38/1, 51-169 Wrocław, Poland